注意!该教程对应ROS视觉套件用户

对象检测是检测图像或视频中特定类别的实例的工艺,如动物、人类等。
在本文中,我将介绍如何使用 yolo3 对象检测模型。

yolov3 简介
YOLO 是 You Only Look Once 缩写,它是一种针对实时处理的对象检测系统。YOLO 的工作方式与大多数其他对象检测架构完全不同,大多数方法将模型转换为多个位置和比例的图像,通过得分找出图中物体可能出现的位置。而Yolo 将单个神经网络应用于完整图像,网络将图像划分为多个区域并预测每个区域的边界框和概率,这些边界框由预测概率加权。


运行YOLO V3
该例程使用RGB-D相机运行,由于Astra驱动不支持RGB-D因此只用到深度
该jetson镜像支持Opencv CUDA加速
- 机器人本地端启动摄像头、YOLO节点
roslaunch lingao_visual lingao_yolo.launch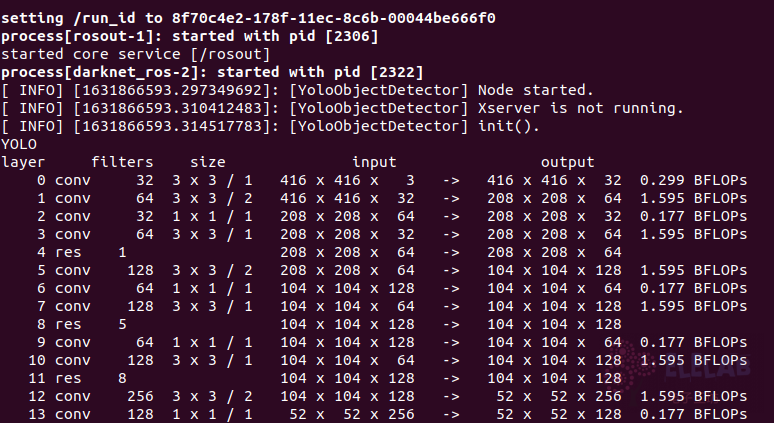
等待初始化启动 -
在远程rqt_image端查看
rosrun rqt_image_view rqt_image_view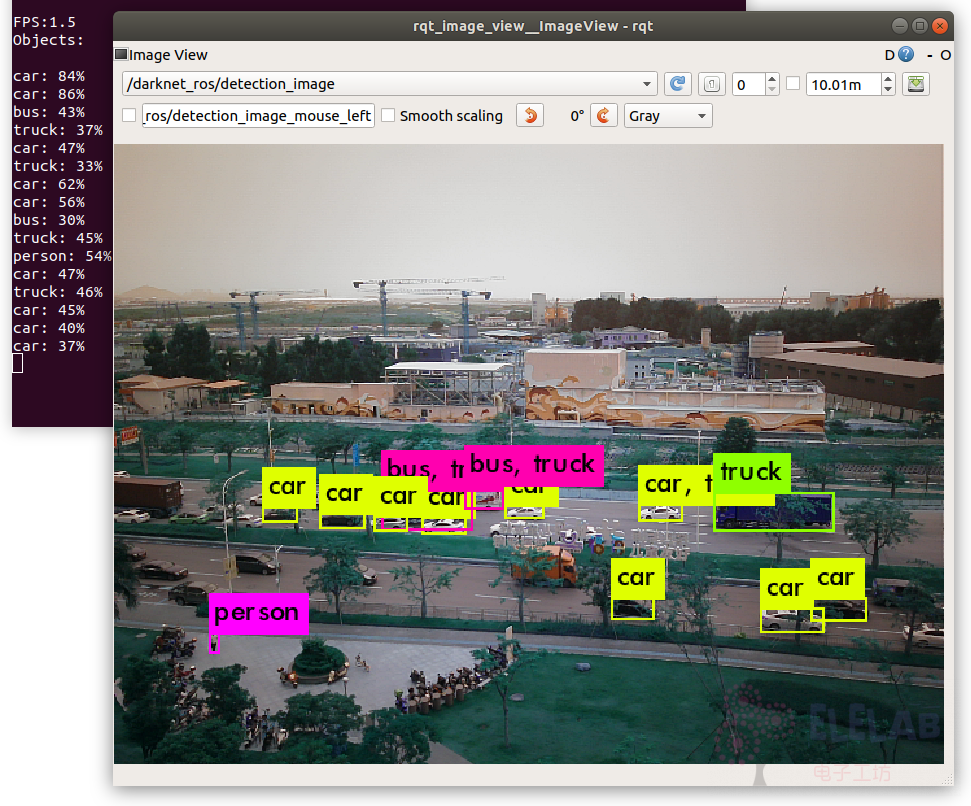
经实际测试,识别精度比较高,但帧率在1.5帧左右,GPU已跑满。在NX上帧率也是不到10帧,特别耗GPU。
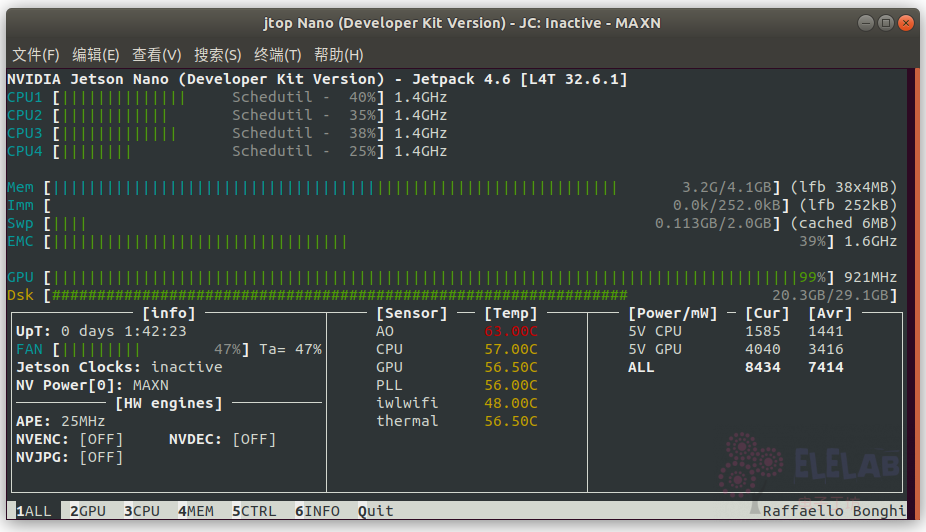
可通过输入jtop查看jetson状态



运行yolov3 tiny、yolov2
-
机器人本地端运行yolo v3 tiny 网络
roslaunch lingao_visual lingao_yolo.launch network_param:=yolov3_tiny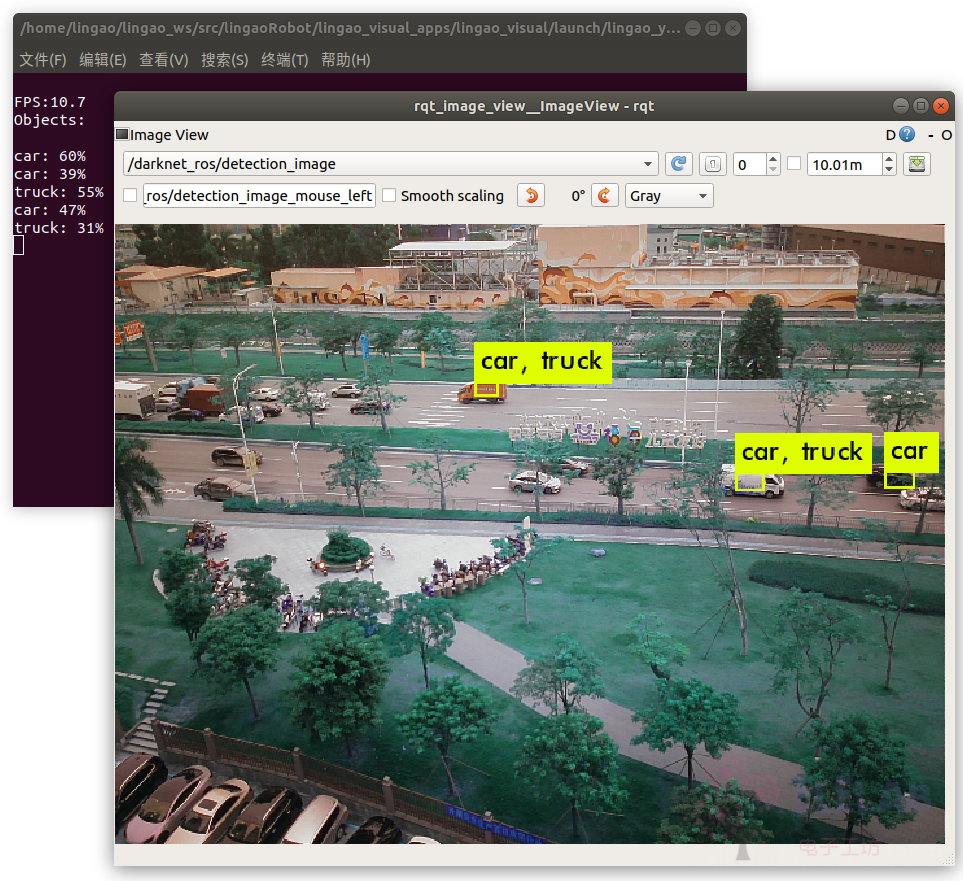
可看到上到10帧,但是识别率比较低 -
机器人本地端运行yolo v2网络
roslaunch lingao_visual lingao_yolo.launch network_param:=yolov2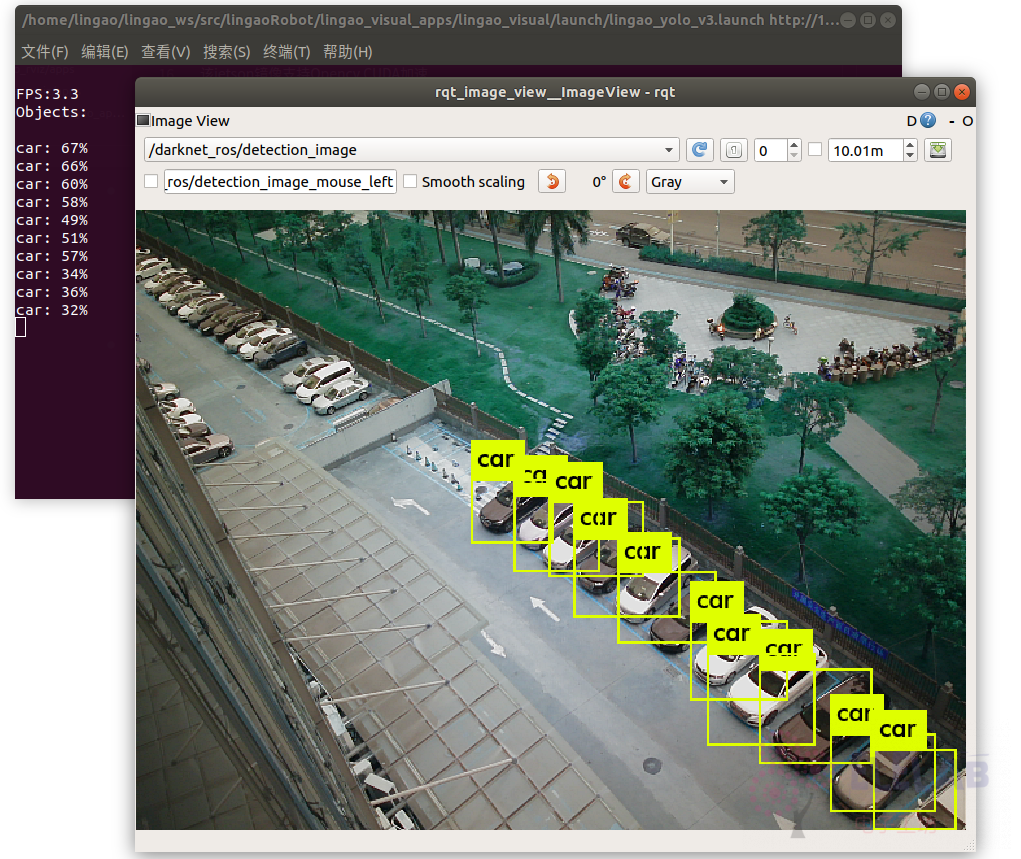
可看到识别率比yolo v3 tiny好,因为yolo v3多路三个不同尺度特征层所以远距离小物品识别率会比较好,但牺牲了一些性能。

